
這幾天的文章會是一系列的,會需要一起看才比較能看懂整個ML模型的輪廓,
然而因為一天能寫的內容量有限,所以我會在前言部分稍微說明我寫到哪。
因為ML模型的訓練階段章節內容會分很多部分,我們要先確認好自己在哪個階段,
以免吸收新內容卻不知道用在內容的什麼地方。
★ 「訓練一個ML模型」的整個過程:這裡以監督式學習(Supervised Learning)為例
| 階段 | 要做的事情 | 簡介 |
|---|---|---|
(訓練前) |
決定資料集與分析資料 | 你想要預測的是什麼資料? 這邊需要先知道 example、label、features的概念。介紹可參考:【Day 15】,而我們這次作為範例的訓練資料集介紹在【Day 19】。 |
(訓練前) |
決定問題種類 | 依據資料,會知道是什麼類型的問題。regression problem(回歸問題)? classification problem(分類問題)? 此處可參考:【Day 16】、與進階內容:【Day 17】 |
(訓練前) |
決定ML模型(ML models) | 依據問題的種類,會知道需要使用什麼對應的ML模型。回歸模型(Regression model)? 分類模型(Classification model)? 此處可參考:【Day 18】,神經網路(neural network)? 簡介於:【Day 25】 |
| (模型裡面的參數) | ML模型裡面的參數(parameters)與超參數(hyper-parameters) 此處可參考:【Day 18】 |
|
(訓練中) 調整模型 |
評估當前模型好壞 | 損失函數(Loss Functions):使用損失函數評估目前模型的好與壞。以MSE(Mean Squared Error), RMSE(Root Mean Squared Error), 交叉熵(Cross Entropy)為例。此處可參考:【Day 20】 |
(訓練中) 調整模型 |
修正模型參數 | 以梯度下降法 (Gradient Descent)為例:決定模型中參數的修正「方向」與「步長(step size)」此處可參考:【Day 21】 |
(訓練中) 調整腳步 |
調整學習腳步 | 透過學習速率(learning rate)來調整ML模型訓練的步長(step size),調整學習腳步。(此參數在訓練前設定,為hyper-parameter)。此處可參考:【Day 22】 |
(訓練中) 加快訓練 |
取樣與分堆 | 設定batch size,透過batch從訓練目標中取樣,來加快ML模型訓練的速度。(此參數在訓練前設定,為hyper-parameter)。與迭代(iteration),epoch介紹。此處可參考:【Day 23】 |
(訓練中) 加快訓練 |
檢查loss的頻率 | 調整「檢查loss的頻率」,依據時間(Time-based)與步驟(Step-based)。此處可參考:【Day 23】 |
(訓練中) 完成訓練 |
(loop) -> 完成 | 重覆過程(評估當前模型好壞 -> 修正模型參數),直到能通過「驗證資料集(Validation)」的驗證即可結束訓練。此處可參考:【Day 27】 |
(訓練後) |
訓練結果可能問題 | 「不適當的最小loss?」 此處可參考:【Day 28】 |
(訓練後) |
訓練結果可能問題 | 欠擬合(underfitting)?過度擬合(overfitting)? 此處可參考:【Day 26】 |
(訓練後) |
評估 - 性能指標 | 性能指標(performance metrics):以混淆矩陣(confusion matrix)分析,包含「Accuracy」、「Precision」、「Recall」三種評估指標。簡介於:【Day 28】、詳細介紹於:【Day 29】 |
(訓練後) |
評估 - 新資料適用性 | 泛化(Generalization):對於新資料、沒看過的資料的模型適用性。此處可參考:【Day 26】 |
(訓練後) |
評估 - 模型測試 | 使用「獨立測試資料集(Test)」測試? 使用交叉驗證(cross-validation)(又稱bootstrapping)測試? 此處可參考:【Day 27】 |
| (資料分堆的方式) | (訓練前) 依據上方「模型測試」的方法,決定資料分堆的方式:訓練用(Training)、驗證用(Validation)、測試用(Test)。此處可參考:【Day 27】 |
★ 從上面的訓練中,找到「最好的」ML模型:【Day 27】
原因:「訓練好一個模型」不等於「找到最好的模型」
| 階段 | 要做的事情 |
|---|---|
(訓練模型) |
使用「訓練資料集(Training)」訓練模型(調整參數),也就是「上方表格」在做的內容 |
(結束訓練) |
訓練到通過「驗證資料集(Validation)」結束訓練(未達到overfitting的狀態前) |
(模型再調整) |
超參數(hyperparameters)調整或神經網路的「layer數」或「使用的node數」(一些訓練前就會先決定的東西) |
| (loop) | (模型再調整)後,重複上述(訓練模型)、(結束訓練),完成訓練新的模型 |
(找到最佳模型) |
從「所有訓練的模型」中,找到能使「驗證用資料集(Validation)」最小的loss,完成(找到最佳模型) |
(決定是否生產) |
可以開始決定要不要將此ML模型投入生產。此時我們可以使用「獨立測試資料集(Test)」測試? 使用交叉驗證(cross-validation)(又稱bootstrapping)測試? |
★小實驗系列:
| 文章 | 實驗內容 |
|---|---|
| 【Day 24】 | TensorFlow Playground 的簡介與介面介紹 |
| 【Day 24】 | learning rate 的改變對訓練過程的影響 |
| 【Day 25】 | 使用神經網路(neural network)分類資料 |
| 【Day 25】 | 觀察batch size如何影響gradient descent |
第三章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
Performance Metrics
Performance Metrics
★ 比較損失函數(loss function)與性能指標(performance metrics):
| 比較 | 損失函數(loss function) |
性能指標(performance metrics) |
|---|---|---|
| 使用時機 | (訓練中) |
(訓練後) |
| 理解容易度 | 很難理解(較抽象) | 很容易理解(較不抽象、很直接) |
| 與商業目標 | 不是直接相關 | 此指標能直接反應於商業目標 |
| 共通點 | 衡量ML模型的指標 | 衡量ML模型的指標 |
課程地圖
在前面的章節中,我們曾在視覺化的網頁中訓練我們的模型,
並使用梯度下降法(gradient descent)優化了我們模型的參數,
我們最後所創造出的模型,透過許多層次的特徵結構,學習到了複雜的非線性關係。
然而,我們在這章節的最後發現這樣的方法可能有問題,
他的後果包含著「訓練時間長」、「最小值為次佳值」、以及「不適當的最小值」。
在這個章節,我們會仔細來討論什麼是「不適當的最小值」,為什麼他會存在,
以及透過「性能指標(performance metrics)」,我們如何能夠得到更好的結果。
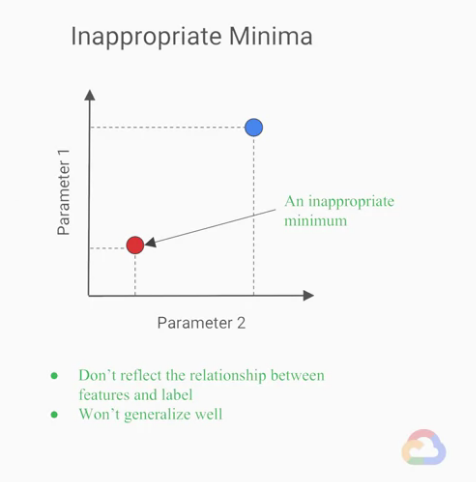
我們可以想像所有在參數空間(parameter space)的點都代表一種策略,
有些點可能不能很好的泛化(generalize),
或者是不能透過模型反應出資料集的正確關係。

舉個例子,當我們正在訓練一個模型,我們想預測停車場的圖片是否有空位,
有一種策略是這樣的:我們不管怎麼樣就預測「所有的車位都是被佔滿的」。
採取這樣的策略,當我們的資料集正值與負值的例子差不多相等時,
這個策略似乎不可能會成功。
但是,如果我們的資料集是傾斜(skewed)的,
也就是某一類的資料集明顯比另外一類多的時候,
例如,我們拿到的圖幾乎車位都是滿的,
預測「所有的車位都是佔滿的」似乎就是個不錯的策略,
而且我們的模型也不需要多花費心力去理解特徵(features)與label的正確關係。
我們期待的結果應該是,我們的模型能夠真正理解「空著的車位」的意思,
預測「車位皆被佔滿」的模型,自然很難泛化(generalize)到其他的停車場也適用。
自己的註:
為什麼會有這樣的事情發生?
我們可以想像每次選擇題的考卷,如果每次我「全選C」就能得到不錯的分數,
那我還花心力去讀書並理解知識幹嘛? 寫C就能夠得到高分了啊!
模型這邊在做的事情,就與上面的例子一樣。
損失函數(loss function)存在嗎?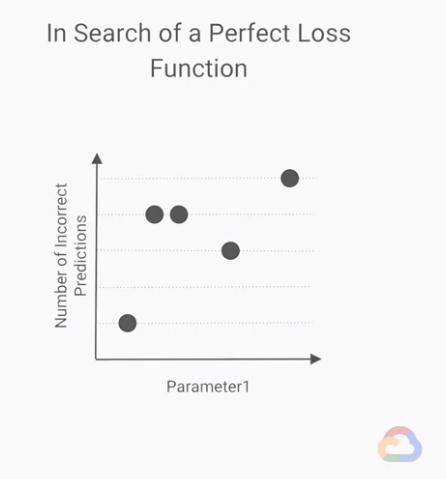
(如果我們的loss值是整數?)
我們很容易將「不適當的最小值」的存在視為是損失函數(loss function)的問題,
如果我們能有一個完美的損失函數(loss function),
就能夠獎勵真正的最佳策略,只處罰不好的策略。
但這是不可能的,我們「想關注的指標」與「梯度下降相符合的指標」始終會存在差距。
自己的註:
上面已經舉例過學生寫考卷的例子了,
這邊也能以類似的例子來比喻,
老師認為的好是「90分」,你認為的好是「60分」,
我們每次都作答到「60分」使自己滿意了,但並不滿足「老師的滿意」。
所以我們一樣回到剛剛討論的停車位的問題。
假設我們依然在對停車位進行分類,
一個完美的損失函數(loss function)應該會幫我們「最小化錯誤預測」的數量。
然而,以這題而言,這樣的損失函數(loss function)應該會是分段的,
他可以取的值的範圍將是整數,而不是實數。
自己的註:
因為車子的數量只能是整數。
但這會是有問題的,問題出在「微分」。梯度下降(Gradient descent)使得我們的權重(weights)有所變化,
反過來說,這也表示我們要能夠對權重(weights)微分,以取得我們的loss,
分段的函數在每個範圍內有差距,雖然TensorFlow依然可以對他們微分,
但loss的表面將不具有連續性,這使得我們在尋找下個參數時更具有挑戰性。
所以我們必須重新定義問題的框架,
與其尋找一個完美的損失函數(loss function),
不如我們應該使用一個新的指標來解決這個問題。
性能指標(performance metrics)
而這種新的度量標準使我們能夠拒絕那些被認定為「不合適最小值」的模型,
我們稱這個度量標準為「性能指標(performance metrics)」,性能指標(performance metrics)與損失函數(loss function)相比有兩個好處。
他能夠更容易地被理解。因為它們通常是可以統計的簡單組合。
性能指標(performance metrics)通常直接與「商業目標」相關。
第二點比較微妙,但我們可得出的結論是:
通常loss會與「商業目標」有共同目標,但不一定每次都對目標有一樣的影響,
有時候,雖然我們的loss很小,但我們在「商業目標」的進展也同樣的很小。
自己的註:
也就是說,「最小化loss」通常是我們的訓練目標沒錯,
但「最小化loss」的情況不代表這樣的模型拿來生產,結果也一定是最好的。
再換句話說,兩個模型訓練的能力一個「+1」、一個「+10」,
這個都叫做「好」,只是「+1」實際能造成的正面影響較小。
而下一章,我們會複習三個性能指標(performance metrics):
並且知道何時該使用這些指標。
coursera - Launching into Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
